On 21 May 2025, John Mueller of Google Search Relations told people to focus on producing "unique, non-commodity content that visitors from Search and your own readers will find helpful and satisfying." That phrase now shapes how Google talks about E-E-A-T in 2026.
In plain English: non-commodity content is content only you could write. It's the piece a reader couldn't get by summarising the top ten search results, or by asking ChatGPT to paraphrase them. Commodity content is the opposite: interchangeable, could be produced by anyone with the same public sources. One of those two is what Google now rewards; the other is what it quietly demotes.
Most advice on how to show E-E-A-T stops at "add an author bio." That's a third of the job. E-E-A-T in 2026 is a build problem, and the build has three parts: write non-commodity content, prove it to humans with a visible trust stack, and expose it to machines with markup that gates rich results and AI Overview eligibility. I audited the top ten results for "how to improve E-E-A-T SEO 2026" on 24 April before writing this. The shared pattern across all ten was some variation of experience, expertise, backlinks, author bios, and HTTPS: useful but partial. None walked through a visible trust stack (reviewer lines, dated update logs, editorial standards page). None treated structured data as a separate gate-keeping layer for rich results and AI Overview eligibility. None mentioned AI discovery files. This post shows all three, using code, screenshots, and real numbers from our own live site.
First-hand data, named figures, specific claims only you can make.
Author, reviewer, update log, editorial standards, all on the page.
BlogPosting schema, FAQPage with anchors, breadcrumbs, AI discovery files.
What Google actually says
Start with the source. On 21 May 2025, Mueller wrote this in the post announcing how to do well in Google's AI experiences:
"People often ask how to make content that's 'what Google wants'. Our answer is that Google wants to show content that fulfills peoples' needs. Focus on making unique, non-commodity content that visitors from Search and your own readers will find helpful and satisfying."
John Mueller, Google Search Relations, Top ways to ensure your content performs well in Google's AI experiences on Search, 21 May 2025.
When I first read this on the day it went live, my reaction was relief. For years Google's advice had been a catalogue of soft nouns: helpful, relevant, quality, useful. "Non-commodity" is different. It's a testable property. You can look at a draft and ask: could any other site have written this, or does this content exist because we specifically wrote it? If the answer is "anyone could," it's commodity.
The second load-bearing quote is the one people keep forgetting. From Google's Helpful Content documentation:
"E-E-A-T itself isn't a specific ranking factor, but using a mix of factors, our systems identify content that seems to match E-E-A-T."
Google, Creating helpful, reliable, people-first content.
I've lost count of the client briefs that ask us to "increase our E-E-A-T score." There is no score. E-E-A-T is the scoring guide Google's quality raters use to judge whether the ranking systems are behaving. The raters' judgments don't tune the rankings directly; they're training signals for the quality-evaluation models inside the core ranking system. That makes E-E-A-T second-order: it influences the models that influence the ranking, not the ranking itself. Once I stopped treating it as a dial you could turn, the work got concrete: stop chasing an imaginary number, start making the trust evidence on the page visible and true so the systems that read the page can recognise what the raters would.
The third quote is the one that actually defines the thing. Google's Search Quality Rater Guidelines, section 3.2 on Originality:
"Consider the extent to which the content offers unique, original content that is not available on other websites. If other websites have similar content, consider whether the page is the original source."
Google, Search Quality Rater Guidelines §3.2.
Read those three in order and the shape becomes clear. E-E-A-T is the scoring guide the raters use. Non-commodity is how that score shakes out. Originality, per Google, is measured against what other sites already publish. A rewrite of "the 10 best WordPress hosts in 2026" that recycles the same ten vendors in a new order is not original. A post that explains what MySQL 8.0 means for a WP7 upgrade, because we were the site that surfaced it, can be.
A year on from Mueller's May 2025 line, Google hasn't walked it back. Three core updates (November 2025, December 2025, March 2026) rolled through without any revised framing; subsequent Search Central posts, Search Off The Record episodes, and Search Central Live talks continued to reference it. Non-commodity is still the governing statement. The three parts that break out of it, write it, prove it, expose it, are the rest of this post.
Part 1: Write non-commodity content in the first place
Before we get to markup, the content has to be worth marking up. Google's own Search Quality Rater Guidelines on Experience are as direct as Google ever gets:
"Consider the extent to which the content creator has the necessary first-hand or life experience for the topic. Many types of pages are trustworthy and achieve their purpose well when created by people with a wealth of personal experience. For example, which would you trust: a product review from someone who has personally used the product or a 'review' by someone who has not?"
Google, Search Quality Rater Guidelines §3.4.
That second sentence is the whole game for a hosting company writing about hosting. We host WordPress sites for a living. We've run migrations, watched caches misbehave at 2am, and rebuilt client setups after DNS disasters. Every one of those is a non-commodity seed. A review site recycling vendor spec sheets is not operating at the same level as an engineer writing from inside a production platform.
You don't have to take my word for what the difference looks like. At Google Search Central Live in Toronto earlier this year, Danny Sullivan projected a slide that made it plain, with three industry examples. It was covered by Search Engine Roundtable and Hobo Web. I've added a fourth row from our own lane so the pattern is obvious.
| Sector | Commodity (demoted) | Non-commodity (rewarded) |
|---|---|---|
| Running shoes | "Top 10 Things to Consider When Buying Running Shoes". Generic advice on sizing, arch support, cushioning. | "Why This Customer's Shoes Collapsed After 400 Miles: A Wear Pattern Analysis". A deep-dive on one runner's gait and the lateral foam failure it caused. |
| Real estate | "7 Tips for First-Time Homebuyers". Generic checklist of pre-approval, location, budgeting. | "Why We Waived the Inspection (And Saved $15k): A Look Inside the Sewer Line". A specific bidding war, exact decision reasoning, the outcome. |
| Interior design | "2024 Kitchen Trends You Need to See". Pinterest roundup of green cabinets and brass hardware. | "Marble vs. Grape Juice: Why I Refused to Install Stone for a Family of Five". Stain tests with grape juice and turmeric, contrarian position, specific client. |
| WordPress hosting (ours) | "Top 10 WordPress Hosting Providers for 2026". The same ten vendors shuffled into a new order, lifted from the SERP. | "WordPress 7.0 Hosting Readiness: What Your Provider Won't Tell You". Surfaced the MySQL 8.0 minimum that almost no other hosting coverage caught. |
The commodity column is what a rival publisher, an affiliate site, or ChatGPT summarising the SERP could produce without leaving their desk. The non-commodity column is what someone who actually did the work can write. Google's position is that the second kind wins in 2026, and demotes the first.
The running case study in this post is a real example. On 23 April 2026 we revised our WordPress 7 hosting readiness piece to add a material fact that almost no other hosting coverage was carrying: WordPress 7 requires MySQL 8.0 as a minimum. During SERP research we checked the big hosting brands, a couple of affiliate sites, and two tech publications. None of them led with the database-version requirement. We found it in the core-development commits and the WordPress core requirements page, added it with a dated Post Update Paragraph, and logged the change in the Update Log block.

That paragraph is small. But it's the kind of small thing a commodity article can't produce, because you can only write it if you went and looked. Writing it is Part 1. Proving it to the humans reading the page is Part 2.
Part 2: Prove non-commodity to humans (the visible trust stack)
Google's rater guidelines, section 2.5.2, ask three questions of every page: who created the content, how it was created, and why. Those questions aren't for the algorithm. They're for the human sitting in front of the page, deciding whether to believe it. The trust stack that follows is the answer rendered in HTML and CSS. The schema comes in Part 3; this part is what the reader can see.
Here's the hero of the article we keep coming back to. Byline, role, avatar, reviewer line, and both the Published and Last reviewed dates, all above the fold:
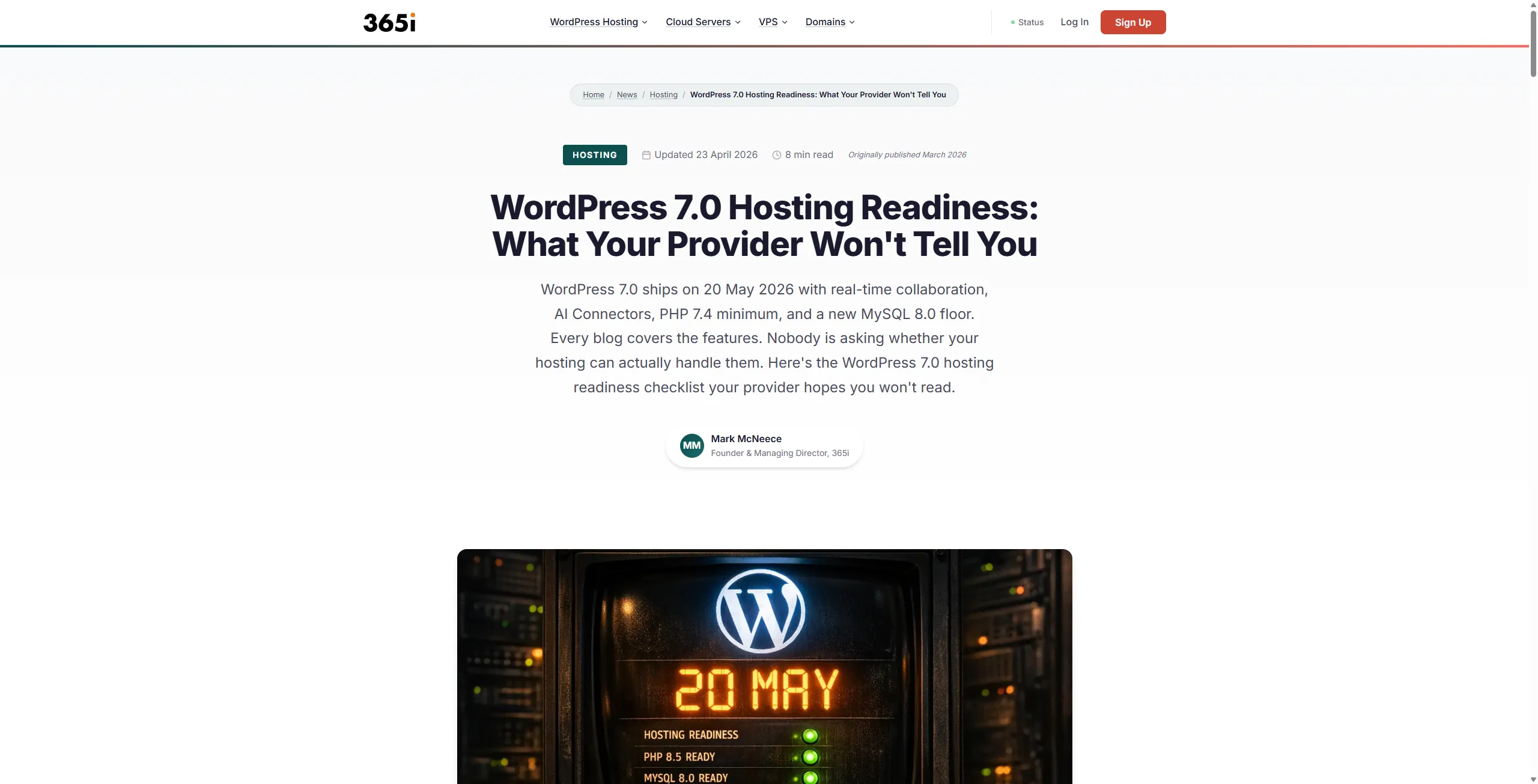
Below the hero, the published line renders a second time next to the reviewer line, with the Update Log block directly under it. This is the exhibit that actually moves the needle with readers. Every time we substantively revise a post, we add a dated entry. Typos and CSS tweaks don't count. A material fact, a corrected claim, a new pricing change, those do.
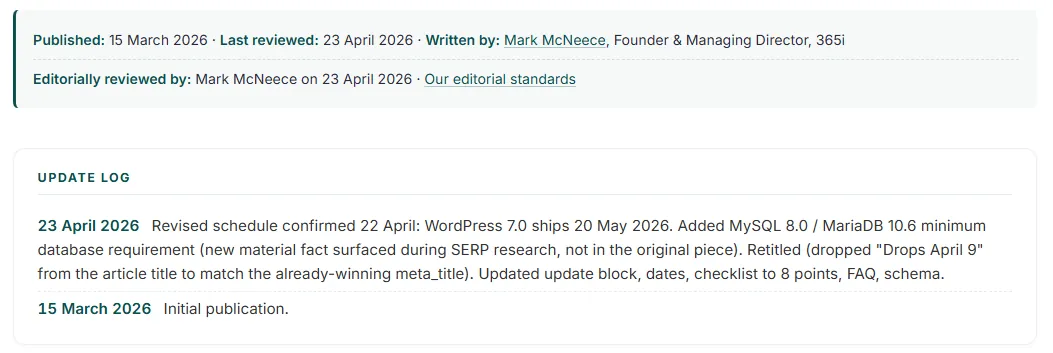
At the bottom of every article there's an author block with a real bio, a real avatar, and a link to our editorial standards page. The avatar isn't stock, it's a photo of Mark. The bio is a description of what he's been doing since 2002, and it's identical across every 365i article.

That editorial standards link is where most small sites stop. They'll ship a bio and call it done. We went further and built a dedicated page explaining who reviews, how corrections are handled, and what our policy is on AI-assisted content. It's a page most readers will never visit. It exists because Google's raters will, and because linking to it from every author box is a small claim we're happy to back up.
The trust stack isn't theoretical. After we revised the main release-date guide across seven months and four Update Log entries, an unsolicited LinkedIn comment appeared under a post about the WordPress 7.0 delay. Someone I'd never met noticed that we'd revisited the earlier posts and logged the changes clearly, rather than just moving on to the next piece, and called it out publicly as editorial integrity.
That's the point of the visible trust stack. A stranger read the Update Log, saw what we'd done, and reached for the words that describe what they were looking at, without prompting. The markup in Part 3 gives machines the same view. The stack in Part 2 means humans can see it first, without parsing JSON.
One warning before anyone lifts this playbook: Google's own Helpful Content documentation flags one easy way to mess it up. Their self-assessment question reads:
"Are you changing the date of pages to make them seem fresh when the content has not substantially changed?"
Last-reviewed dates only work if the content has actually been reviewed. Typos and whitespace tweaks are not revisions. Substantive factual changes are. We log material changes in the Update Log block above; we do not bump dates for the sake of it.
Part 3: Expose non-commodity to machines (markup for eligibility)
Read this sentence before the rest of the section, because the rest of the section depends on it: schema is not a ranking factor. Google has said this since 2018 and hasn't shifted position. Structured data will not raise your rankings. What it does do is gate eligibility for rich results, AI Overview citations, and "Jump to" sitelinks. Schema is a discoverability mechanism, not a ranking lever, and the common post telling readers to "add schema to rank higher" is wrong.
So why bother? Because in 2026, half of Google's surface area and all of the AI engines pick winners from the pool of pages whose markup lets them be picked. Get the markup right and you're in the pool. Skip it and you aren't.
Three blocks do most of the work on a news article. First, the BlogPosting shape. Three fields inside it do most of the work: dateModified has to match the visible "Last reviewed" line in the hero or Google's raters will flag the mismatch; speakable tells Google Assistant which selectors to read aloud; and hasPart, the most underused field in the spec, is one of the signals Google uses when deciding whether to surface "Jump to" sitelinks under the page title. Firing isn't guaranteed (sitelink heuristics are a blend of schema, TOC detection, and query match), but shipping hasPart correctly is the part you actually control. Look for all three fields in the block below:
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"headline": "...",
"datePublished": "2026-03-15T10:00:00+00:00",
"dateModified": "2026-04-23T08:00:00+00:00",
"author": { "@type": "Person", "name": "Mark McNeece" },
"publisher": { "@type": "Organization", "name": "365i" },
"speakable": {
"@type": "SpeakableSpecification",
"cssSelector": [".article-hero__title", ".article-hero__excerpt"]
},
"hasPart": [
{ "@type": "WebPageElement", "@id": "#what-changed",
"name": "What Changed", "url": ".../#what-changed" },
{ "@type": "WebPageElement", "@id": "#who-is-affected",
"name": "Who Is Affected", "url": ".../#who-is-affected" }
]
}On our site we build hasPart from the same $toc_sections array that powers the on-page table of contents, so the two can never drift. Change a heading, the schema follows.
Second, FAQPage with an @id on every Question. The @id is the detail most FAQ schema implementations miss, and it's the one that matters. Without it you get a valid FAQPage but nothing the AI engines can deep-link back to. With it, an AI answer can cite a specific question inside your page and the click from that answer lands the reader on that exact Q&A. Watch the @id and matching url fields in the example below:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"inLanguage": "en-GB",
"mainEntity": [
{
"@type": "Question",
"@id": "https://www.365i.co.uk/.../#faq-is-eeat-a-ranking-factor",
"name": "Is E-E-A-T a ranking factor?",
"url": "https://www.365i.co.uk/.../#faq-is-eeat-a-ranking-factor",
"acceptedAnswer": {
"@type": "Answer",
"text": "No. Per Google's own Helpful Content documentation..."
}
}
]
}That same @id anchor has to exist as a real DOM id on the page. The schema and the HTML live or die together; one without the other is a broken link.
Third, BreadcrumbList. Short, uncontroversial, and the single easiest way to get your site's URL structure displayed in search results instead of the raw URL:
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{ "@type": "ListItem", "position": 1, "name": "Home", "item": "https://www.365i.co.uk/" },
{ "@type": "ListItem", "position": 2, "name": "News", "item": "https://www.365i.co.uk/news/" },
{ "@type": "ListItem", "position": 3, "name": "This article" }
]
}BreadcrumbList replaces the ugly URL path under the title with a tidy Home > News > Title trail. It's a 10-line addition and it ships on every page of this site.
Author entity signals: where on-page meets off-page
Before the validator screenshots, the single most common gap between sites that claim E-E-A-T and sites that actually earn it: the Authoritativeness A is won mostly off-page, not on it. The author field in the BlogPosting block above just says "name": "Mark McNeece". On its own, that's a claim. What turns it into something Google can verify is sameAs: an array of URLs pointing to the same person on other reputable sites. LinkedIn, X/Twitter, GitHub, a Wikipedia entry if there is one, guest articles on third-party publications, conference talks. That's how Google's Knowledge Graph resolves a name on your page to an entity it already has a record of.
"author": {
"@type": "Person",
"name": "...",
"url": "https://yoursite.com/author/slug/",
"jobTitle": "Founder, Your Company",
"sameAs": [
"https://www.linkedin.com/in/your-profile/",
"https://x.com/yourhandle",
"https://github.com/yourusername"
]
}sameAs only works if the profiles on the other end are real. A LinkedIn URL pointing to a bare profile with no connections and no activity is worse than no URL at all, because Google checks, and rater guidelines §3.3 explicitly ask raters to look up the people a site names. Click every URL you list, make sure each is live, current, and obviously the same person. The same discipline applies to the publisher Organization: our LocalBusiness schema in the footer carries its own sameAs array pointing to company profiles, directory listings, and the sister sites we own.
A visible byline on a new domain with no off-page footprint is a claim. The same byline on a site where the author has a decade of public talks, published articles on reputable sites, and a resolved Knowledge Graph entry is an entity. The on-page stack in Part 2 is necessary; it isn't sufficient without the off-page signals this section names. If you only ship part of the stack, ship this part.
How to check whether you have a Knowledge Graph entity today, without waiting for one to show up in a Google search: (1) search your own name in Google and look for a Knowledge Panel in the right-hand rail. If it's there, you already have an entity Google is showing publicly. (2) If no panel renders, query the Google Knowledge Graph Search API directly with your name. An entity can exist in Google's graph without being shown to users, and the API will tell you if one does. (3) The Kalicube knowledge-panel tools wrap the API with a friendlier interface if command-line APIs aren't your thing. No entity in any of those three means the work is off-page authority building, not more on-page markup.
Live schema in source, and how it validates
Here's what all three blocks actually look like on a live page. This is the JSON-LD block on our WordPress 7 hosting readiness article, viewed in source:

dateModified, speakable, and hasPart in context.Validating it matters more than writing it. The Schema.org Validator is the independent third-party check. Our article passes with five schemas detected and zero errors, zero warnings:
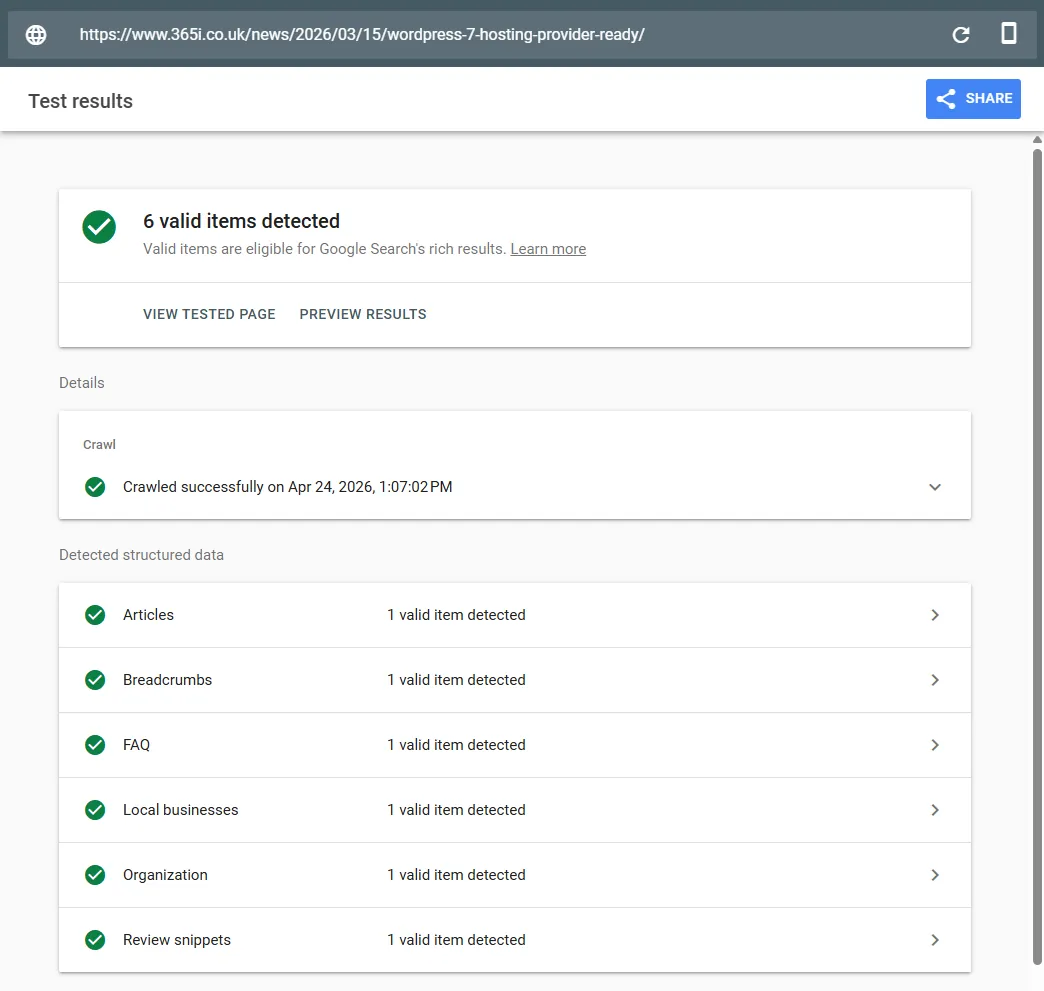
Google's own Rich Results Test is the harder grader. It doesn't just check validity; it confirms which rich-result surfaces the page is eligible for. Ours comes back with six valid items:
One more layer worth shipping: AI discovery files. These are plain-text files at your domain root that tell AI crawlers who you are, what you publish, and what they can and can't use. The three most useful are llms.txt, ai.txt, and robots-ai.txt. We wrote our guide to writing a proper llms.txt file that covers what belongs in it and what to leave out. The open specifications for all three are maintained by the AI Visibility project on our sister site.
How we shipped it, and what happened
We shipped the full visible trust stack on 365i.co.uk at the end of November 2025, with the last pieces (reviewer lines on older articles, Update Log blocks, author bio expansion) going live in the first week of December. The editorial standards page went up the same week. Nothing else about the site changed in that window: same hosting, same theme, same URL structure.
One thing worth stating up front, before the chart: 365i isn't a household name, and we aren't a high-traffic site. The baseline here is small, so the lift below is a real shift for us, not publisher-scale numbers. Read the chart with that in mind. The more interesting story comes after the numbers, in what actually changed about the visitors we do get.
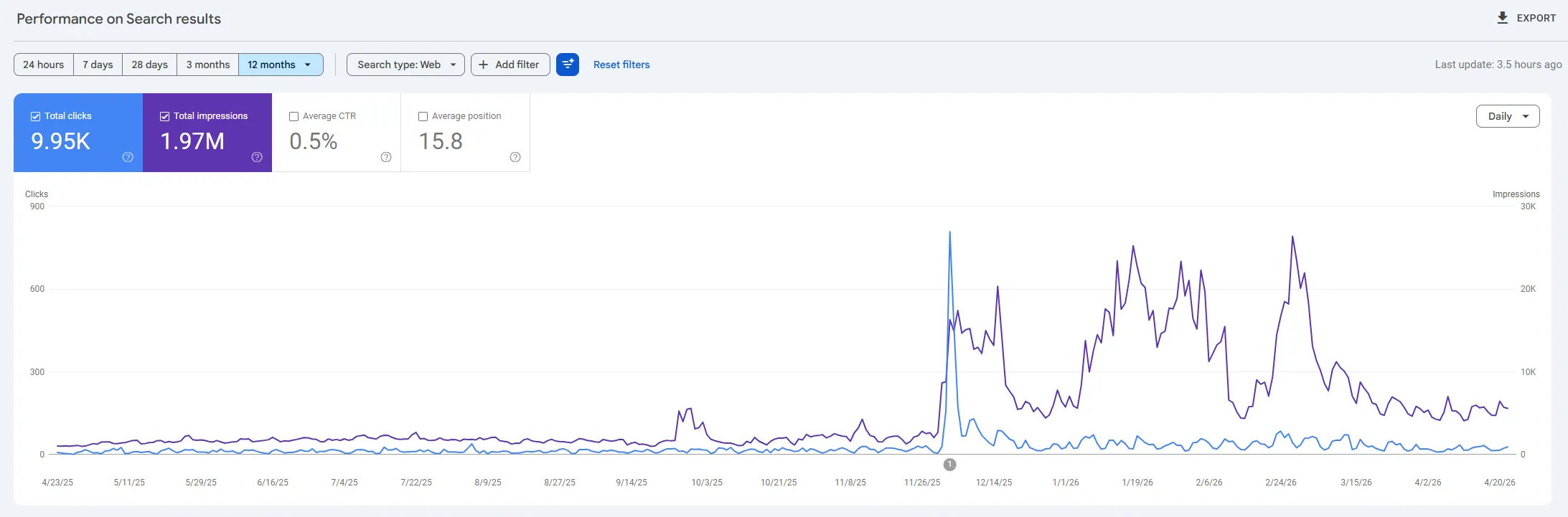
The shape of that chart tells the story better than we can. Three things moved together at the inflection point on Monday 1 December 2025.
CTR roughly doubled, and held. Across the 12 months shown, site-wide CTR averaged 0.5%. The pre-December baseline sat around 0.3%; since the inflection, CTR has held closer to 0.6% and stayed there through April. On the single sample query we were tracking on 1 December itself, GSC recorded 29 clicks against 8,676 impressions, a CTR of 0.33%: right on the pre-change baseline, captured on the day of the change.
Daily impressions roughly tripled, then held. Pre-December the baseline ran at 5,000 to 10,000 impressions per day across the whole site. Post-December the sustained daily level has been 15,000 to 25,000, with peaks near 30,000. Five months on, the new baseline hasn't decayed.
Average time on article roughly tripled. Before December, a large share of visits bounced within 10 to 15 seconds, dragging the per-article average below a minute. Since December, engaged readers have been holding at three to four minutes on news articles. Pages per session rose with it. Site-wide engagement averages in GA4 are lower because they pool article reading time with short homepage and service-page visits; the per-article figure is what moved.
Totals across the 12 months to April 2026: 9.95K clicks, 1.97M impressions, 0.5% average CTR, 15.8 average position.
Here's the more interesting story. What changed more than the scale is the quality of the traffic. Post-December we've been signing up more new customers per month than before, selling more domains and more hosting, and fielding materially fewer "who are you and what do you do?" calls and contact-form questions. The information had always been on the site; readers just weren't reading it until the visible trust stack made it worth reading. A byline, a reviewer line, a dated Update Log, and a linked editorial standards page apparently answer more pre-sales questions than our About page ever did.
Scale matters too, because a small sample can be noise. The stack ships across all 105 published articles. 100% carry reviewer lines (the reviewed_by and reviewed_on fields in each article's data entry). 100% carry "At a Glance" key_points boxes. 100% carry an updates array with substantive revisions logged. 12 of the 105 are flagged as Discover-eligible news posts with full NewsArticle schema and a Google News sitemap entry.
Two honest notes before anyone reads the chart as proof of causation. First, Google's December 2025 core update ran in the same window, and a lot of sites saw Discover traffic collapse at the same time. The chart above deliberately filters to Search only so the two surfaces don't blur together; what's shown is a Search-channel change, not a Discover rebound. Second, we can't rule out that some of the Search lift came from the update rather than the editorial stack we shipped. What we can say is the inflection is dated, sharp, and has held for five months on the Search channel. The pre-December baseline never returned. The editorial stack was the biggest change we made in that window by a wide margin. Call it correlation; don't call it proof.
Why this matters more in 2026: AI Overviews, ChatGPT Search, and Claude
Worth remembering: Mueller's 21 May 2025 "non-commodity content" post wasn't about classic search. The post's actual title was "Top ways to ensure your content performs well in Google's AI experiences on Search." The non-commodity line was published as Google's guidance for AI search specifically.
Liz Reid, VP of Search at Google, framed AI Overviews source selection in Google's own launch post. The published guidance on which sources get picked is thin, but the direction is unambiguous: high quality content from the open web, selected for the specific question. Not every page competes for every AI Overview slot; the pages that compete are the ones with clear information gain over what the model already knows.
Anthropic's web search launch post is explicit on the same point. In the announcement of Claude web search, Anthropic says Claude "provides direct citations" so readers can verify the sources. Inline citations aren't decoration; they're the mechanism by which a page with a unique fact ends up named in an AI answer. OpenAI says something similar in the ChatGPT Search launch post, emphasising "original, high-quality content" from publishers.
Here's the thing that changes in 2026. An AI engine answering a question picks one or two sources to cite, not ten. That's a harder bar than ranking ten results. Commodity content has nowhere to be cited from in an AI answer, because the model already knows what every other commodity page says. Non-commodity content, with a named author, a dated update log, a unique fact or number, a source citation another page doesn't have, is what the AI picks up and names.
Observed behaviour is still messier than the stated direction. In April 2026 AI Overviews regularly cite Reddit threads, forum posts, and thin affiliate lists when the query matches. Perplexity will sometimes cite the same top-10 a standard search returns. The stated direction from Google, Anthropic, and OpenAI is to prefer named, verifiable, source-citable content. The algorithms haven't fully caught up yet. Aligning the content stack to the stated direction now is cheaper than catching up to it after the next iteration lands.
This isn't theoretical any more. Here's 365i's own Google Analytics for the 90 days to 23 April 2026, showing real referrals from AI engines to the site:
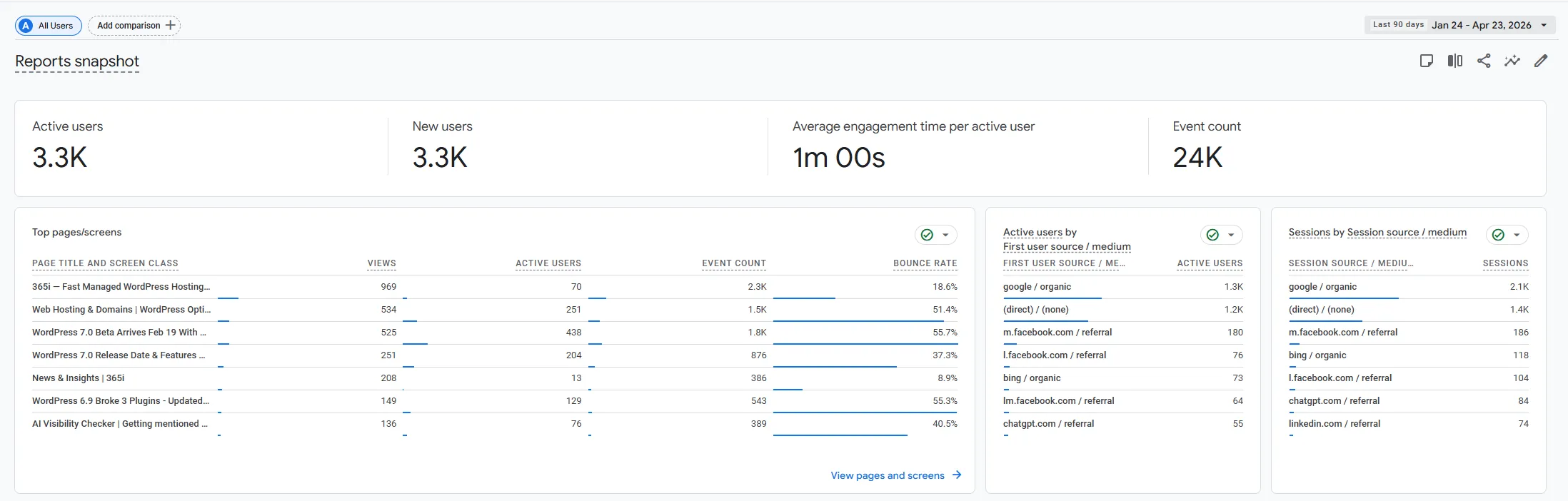
That chatgpt.com/referral line didn't exist a year ago. To see what's actually driving it, the more useful view is the answers themselves. Both of the two answers below were captured on 24 April 2026 in ChatGPT Temporary Chat mode: no chat history, no memory of 365i, no prior conversation, no logged-in personalisation. These are the answers any fresh ChatGPT user asking the same commercial-intent questions would get today.
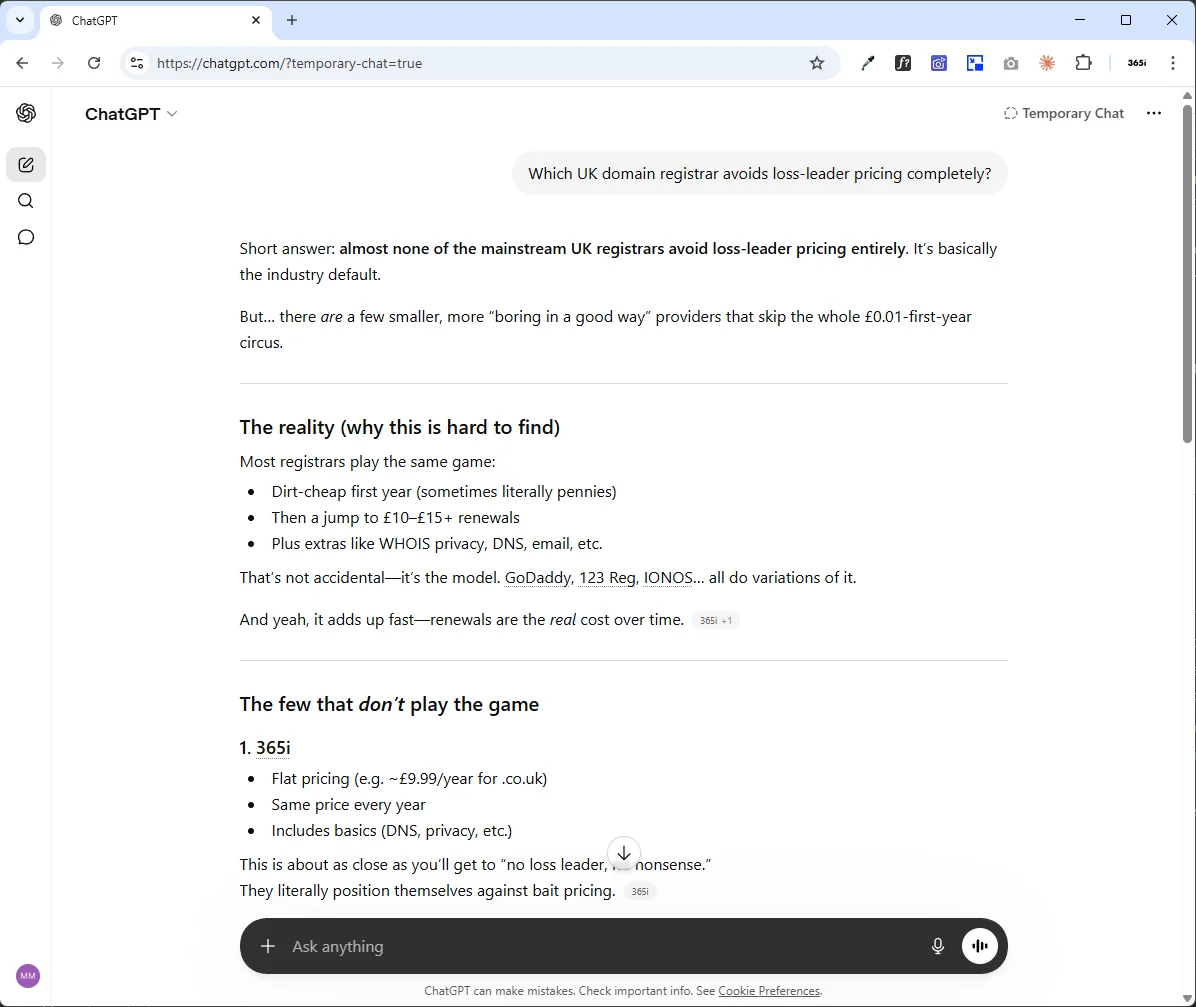
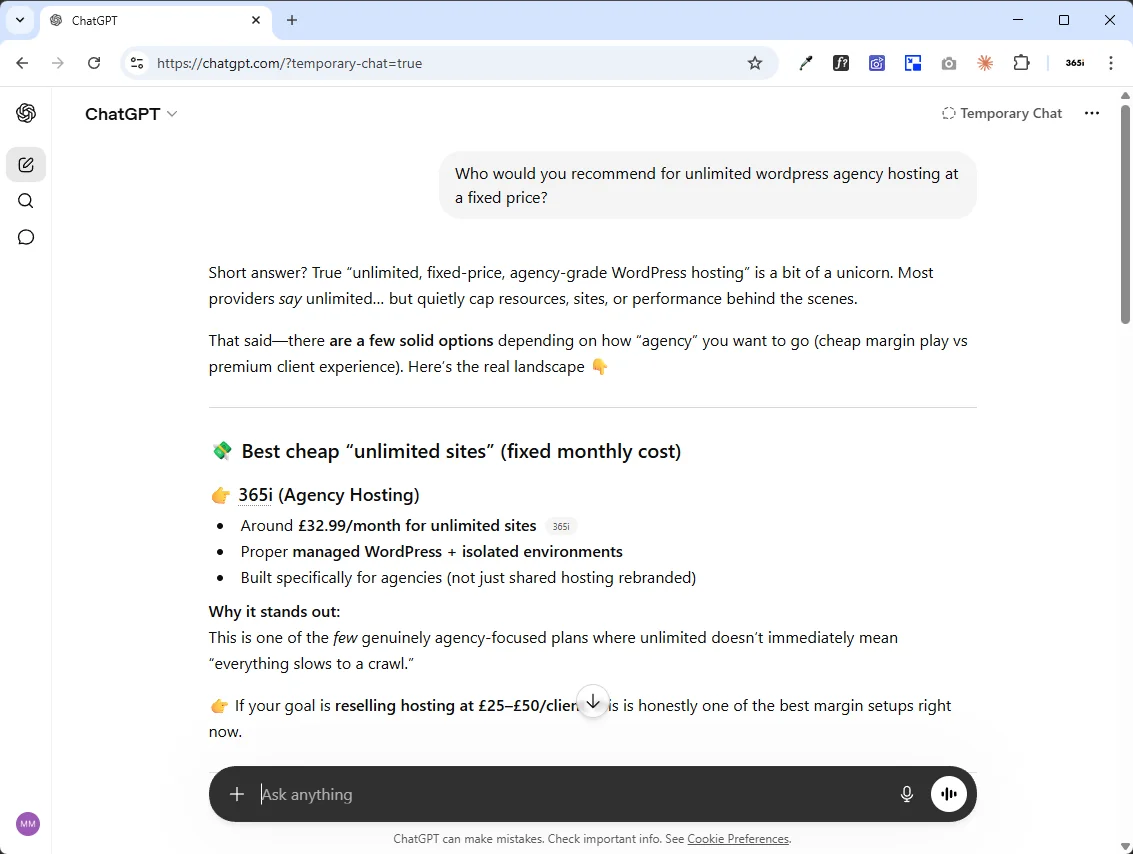
Two observations worth stating explicitly. First, these are commercial-intent queries: the "pick one or two sources" moment this whole post argues about. ChatGPT doesn't line up ten options; it picks the ones it trusts and names them with inline citation pills. Second, the reasons ChatGPT gives for recommending 365i ("flat pricing", "same price every year", "one of the few agency-focused plans that isn't just shared hosting rebranded") are paraphrases of the non-commodity positioning visible on our own pages. The model isn't inventing the framing; it's surfacing what we say about ourselves, because the content is named, dated, schema-marked, and clearly distinct from the commodity competitors it's contrasted against. This is the payoff of the whole three-part build, captured in two screenshots.
What we don't yet have is a screenshot of 365i content cited inside a Google AI Overview panel on the SERP itself. AI Overview panels are a harder bar than ChatGPT Search citation, and we'll add one here the first time we see our content named inside one. Reporting the evidence we have (the ChatGPT answers above, the GA referral data) rather than the evidence we'd like to have is part of the same discipline the rest of this post is about.
Want to know whether your own site can be discovered, interpreted, and cited by AI? The free AI Visibility Checker on our sister site scores you out of 10 against the open standard: AI discovery files, crawler access, identity consistency, and structural readiness. An optional AI Snapshot add-on runs eight live ChatGPT queries to see how the model actually describes your site.
The 9-point non-commodity checklist
Here are nine concrete moves. Do all nine and you've shipped the full stack: the writing, the visible human trust layer, and the machine-readable markup. Skip any one of them and the build leaks somewhere. They're ordered from "hardest to fake" to "easiest to ship".
One note on the schema shape of this checklist before you read it. The checklist below is emitted as HowTo schema on the live page. Google restricted HowTo rich results in August 2023 to DIY-style topics, which means SEO and editorial how-tos like this one won't produce a HowTo carousel on the SERP. That's fine. HowTo schema still does two useful jobs: it lets AI engines parse the steps as discrete items with their own anchor URLs, and it preserves the semantic structure for voice assistants and accessibility tooling. We ship it for those reasons, not for the SERP display it no longer earns.
-
Write something only you could write.
First-hand data, a named figure, a counterfactual, an anecdote from real client work, a number you measured yourself. If another writer with the same public sources could produce the same paragraph, it's commodity. The non-commodity test is simple: imagine a competitor with identical research; what's left after you strip out the overlap is your actual edge.
How to verify: pick any paragraph in your draft. Could a competitor with the same public sources produce it word-for-word? If yes, rewrite it with something you know that they don't. -
Visible byline on every post.
Name, role, avatar, all linked to an author page that actually exists and is crawlable. Not hidden in a meta tag, not buried in the footer. The byline is the single cheapest Authority signal and the one most small sites still get wrong by defaulting to "Admin" or hiding the author entirely.
How to verify: view source on your latest post. The reader needs to see the name on the rendered page, not just in<meta name="author">. Click the name; the author page should load. -
Visible "Editorially reviewed by [name] on [date]".
Sits adjacent to the published line in the article header. On single-person sites it's fine if author and reviewer are the same person: declare it openly rather than hiding it. Hiding it looks evasive; declaring it looks honest, which is the point.
How to verify: look at the article header on a live post. The reviewer line should render as HTML text on the page, not only inside the JSON-LD block. -
Published and Last reviewed dates in the body.
Both dates, rendered as visible text, not only present in schema. Readers need to see them to trust a dated claim. Google's raters are instructed to look for them per the Search Quality Rater Guidelines §3.3.
How to verify: load the article in a browser with JavaScript disabled. Both dates should still appear. If they vanish without JS, they're not actually rendered. -
Update Log block on substantively revised posts.
Factual changes count; typos, CSS tweaks, and whitespace don't. Each entry is dated, with a one-line note explaining what changed. A silent absence is fine on fresh posts; a missing log on a post that's been revised five times is the red flag.
How to verify: greparticles.phpfor the'updates'key. Every post you've materially revised should have an entry there; every such entry should render on the live page. -
About the author box at the end.
A real bio, a real photo, a linked role, and two outbound links: one to the author page, one to your editorial standards page. The standards-page link is what separates a competent bio from a claim of editorial process.
How to verify: scroll to the bottom of the article. The bio should be there, with both links working. Click the standards link; the page should load and not be noindexed. -
BlogPosting schema with
dateModifiedmatching the visible reviewed-on date. Sync is non-negotiable. Do not bumpdateModifiedwithout actually revising the content. A mismatch between schema and visible text is the kind of thing Google's Helpful Content self-assessment explicitly flags.
How to verify: view source, find the JSON-LD block, and confirmdateModifiedmatches the visible Last reviewed date to the day. Run Schema.org Validator; it should parse without errors. -
hasPartarray synced with your on-page TOC. Unlocks Google "Jump to" sitelinks. On our site, both the visible TOC and the schemahasPartare built from a single$toc_sectionsarray so they can't drift. If you're maintaining them separately, one will fall out of sync the first time you edit a heading.
How to verify: run Google's Rich Results Test.hasPartentries should appear under the Article result, and every entry should match a real anchor on the page. -
FAQPage schema with anchored Questions and AI discovery files exposed.
Every Question gets an
@idthat matches an on-page DOM id, so AI engines can deep-link to a specific Q&A. At the domain root, shipllms.txt,ai.txt, androbots-ai.txtso AI crawlers know who you are and what's safe to cite.
How to verify: Rich Results Test should report a valid FAQ result with the correct number of questions. Requesthttps://yourdomain/llms.txt; it should return 200, not 404.
A worked example: applying the stack to a local-services site
Everything above is hosting-flavoured because that's our day job. The pattern transfers cleanly across sectors, and the cleanest test of that is a brand-new site in a completely different niche, built from scratch with the full stack in place from day one.
In April 2026 we built and launched lockerfella.co.uk, an independent locksmith covering South Staffordshire and the West Midlands. Local services is a useful test case because the competition is brutal in a specific way: lead-generation aggregators, franchise networks, and AI-spun "24/7 emergency locksmith UK" landing pages dominate the SERP. None of them have a named human, a real address, or a verifiable credential. That gives a single-operator independent who actually does the work an unusually clean lane to demonstrate E-E-A-T, provided every page is built to show it.
Here's how the three-part stack maps onto a real local-services site, page by page.
Write: 18 dedicated area pages instead of one generic "areas covered" list
The non-commodity move on a local-services site is to refuse the temptation to ship one "we cover the West Midlands" page and call it done. The areas page lists 18 towns, and every one of them is a dedicated page at /areas/{town}/ with the postcodes covered, the response time from the Brewood base, and the named villages within each catchment. /areas/wolverhampton/ isn't /areas/birmingham/ with the town name swapped; the postcode lists are different (WV1 to WV11 versus B1 to B98), the response times are different, the local landmarks named in the copy are different. That's the structural fingerprint of content written by someone who actually drives the routes.
Compare that against a typical competitor. A franchise network's local landing page lists the same six bullet points across every town. A lead-gen aggregator's page lists no postcodes at all. Both fail the originality test in §3.2 of the rater guidelines: if another site has the same content, you're not the original source. Eighteen postcode-specific pages with named neighbouring villages can't be produced by a writer in another county.
Prove: one About page that ships the full visible trust stack in one place
The About page is the worked example of the entire Part 2 above. Every signal a SQRG §2.5.2 rater is asked to look for is on that page, with dates and named institutions:
- Named owner (Sean Hamilton), photo, and a personal "I run this; one man, one van, one phone number" line that no aggregator can match.
- Certificate of Locksmith Skills, with the issuing institution named (A J Am Locksmiths) and the specific skills covered (cylinder, mortice, padlock, wafer, euro lock picking, re-keying, mortice bypass).
- DBS check with the issue date (8 April 2026) and the result ("none recorded") on display.
- £1M public liability insurance with the named insurer (Simply Business) and the renewal date (March 2027), so the claim is checkable rather than aspirational.
- Real registered address (Brewood, ST19 9HR) and direct phone number, both repeated in the LocalBusiness schema in Part 3.
- 12-month workmanship guarantee and a stated no-call-out-fee policy, both surfaced as specific commitments rather than marketing language.
The point isn't that any single one of these signals is novel. It's that they're all on a single page, with dates, with names, with physical artefacts (the certificate, the photo ID, the van). The cost of faking all of them simultaneously, on one page, with checkable details, is higher than the cost of doing the work. That's exactly the wager E-E-A-T is meant to reward.
Expose: LocalBusiness, Service, and FAQ schema, all anchored
The machine layer follows the same pattern as Part 3 above, with the schema types swapped for the sector. LocalBusiness instead of BlogPosting. A Service block per service offered, each with its own price, area served, and parent provider link. FAQPage with anchored questions on every page that has FAQs. BreadcrumbList everywhere. Every @id resolves to a real DOM anchor on the page; every page passes Google's Rich Results Test with zero warnings.
Twelve days after launch, "Brewood Locksmith" was returning lockerfella.co.uk at #1 on Google, ChatGPT, and Gemini, with a fresh domain and no backlink campaign. We covered the launch numbers in the Lockerfella 100-PageSpeed case study; what's worth pulling out here is that the ranking lift on a brand-new domain wasn't from authority signals (there weren't any yet). It was from being the only result in that local SERP that could plausibly be ranked on E-E-A-T at all. The aggregators and franchise networks couldn't beat a site where the named owner, the credential, the address, the insurance, and the area-specific content all reinforce each other.
If you want the fuller, evidence-first version of the same argument framed against Google's 15 May 2026 non-commodity guidance, we wrote it up as The Receipt Test: a non-commodity local business website case study. That follow-on walks the site page by page against Google's own definition of non-commodity content, captures Lockerfella's live AI Search visibility across Google, Gemini and ChatGPT, and names the test we now apply to every page on every site we build. That test sits inside a wider set of build rules, written up as the standard every site in the group is built to, with the measured evidence for each rule rather than the rule on its own.
If you're applying the stack outside hosting, the lesson is portability. The schema types change. The visible-trust pattern doesn't. Named human, dated credentials, named institutions, real addresses, sector-appropriate proof. Then mark every claim up so the machines can see what the humans already can.
What this doesn't fix
Worth being blunt about the limits. Shipping this stack does not rescue every page and it does not replace the substance of the writing.
You cannot hack your way to E-E-A-T by marking up a thin page to look trustworthy. Thin content in a pretty wrapper is still thin. Schema doesn't rescue topical irrelevance: a well-marked-up post on a topic your site has no business writing about will still struggle against a site with real topical authority. Link profiles, internal linking, and topical depth all continue to matter, and none of them are addressed here.
Site-wide quality matters more than page-by-page polish. In Google's March 2024 core update announcement, the team confirmed what used to be a separate "Helpful Content system" had been folded into the core ranking system, assessed continuously. The signal still works site-wide: one great post with a perfect trust stack doesn't save a site where the rest of the archive is thin or scraped. The pattern in this post has to scale across every article that's indexed, not just the flagship pieces. Shipping the stack on five posts while ninety-five stay bare is a recipe for the site-level quality signal to hold you back, regardless of how well the five are built.
Topical authority at the site level is a prerequisite, not an output. 365i has been publishing about WordPress hosting for over twenty years; the trust stack in this post was bolted onto an existing body of work Google already recognised. A brand-new domain shipping the same stack will wait longer for signal because the site entity has no topical history yet. The stack amplifies topical authority; it doesn't substitute for it.
Off-page author authority is the other half of the A. Everything in Part 2 and Part 3 builds the on-page signals. None of it replaces a real off-page footprint for the people you name as authors: LinkedIn, public talks, publications on third-party sites, a sameAs array that actually resolves. A site with perfect schema and an author with no off-page presence is still a claim without verification.
Evidence scope is worth stating plainly too. Every screenshot, every GSC number, every GA referral in this post is from one property: 365i.co.uk. That's an honest single-property case study, not a benchmark. We have since shipped the same approach on a brand-new client site, with similar early indicators: see 100 mobile PageSpeed at launch: the Lockerfella case study, where the non-commodity area-page pattern produced #1 rankings on Google, ChatGPT, and Gemini for "Brewood Locksmith" within 12 days of launch. If you run the same build on your own property, your comparison against your own pre-build baseline is what would generalise the claim.
YMYL topics (Your Money or Your Life: medical, financial, legal) raise the bar further. Rater guidelines §2.3 ask for "a very high E-E-A-T" on those pages, and a hosting-company bio won't cut it for a page telling readers about cancer treatment or mortgage advice. Match the trust stack to the topic you're qualified to write about.
Everything in this post builds the trust layer. It does not replace the substance layer, the sitewide quality layer, the topical-authority layer, or the off-page entity layer. Get the writing right first; then make the trust visible; then keep the rest of the archive at the same bar.
FAQ
Eight direct answers to the questions people actually ask when they read this.
Is E-E-A-T a ranking factor?
No. Per Google's own Helpful Content documentation, E-E-A-T itself is not a specific ranking factor. It's the scoring guide human quality raters use to judge pages, which in turn trains the core ranking systems through feedback. Confusing the scoring guide with a ranking score is one of the most common E-E-A-T mistakes you can make.
What does "non-commodity content" actually mean?
Content only you could write. First-hand, named, numbered, counterfactual. The term was used verbatim by Google's John Mueller on the Search Central blog on 21 May 2025: "unique, non-commodity content that visitors will find helpful and satisfying". The working test: if another writer with the same public sources could produce the same paragraph, it's commodity. If they couldn't, it isn't.
Does schema markup improve my rankings?
No. Schema is an eligibility gate for rich results, AI Overview citations, and "Jump to" sitelinks. It's a discoverability mechanism, not a ranking lever, and Google has held that position since 2018. Adding schema won't lift your rankings; what it does is make your non-commodity signals machine-readable so Google and the AI engines can actually surface them.
How often should I update old posts?
When there's a substantive change, never on a schedule. Google's own Helpful Content self-assessment explicitly flags dates bumped without real revision. Typos and whitespace tweaks are not revisions. A factual correction, a new data point, or a revised conclusion is. Log the substantive ones in an Update Log block so readers and raters can see the change was real.
Do AI Overviews use E-E-A-T?
Google hasn't published AI Overview source-selection signals, and observed citation behaviour in April 2026 is still uneven. AI Overviews regularly cite Reddit threads, forum posts, and thin affiliate lists when a query matches. But the stated direction from Google (Mueller's "non-commodity" guidance, Reid's AI Overview posts), Anthropic (inline citations in Claude web search), and OpenAI (ChatGPT Search's "original, high-quality content" framing) all point the same way. Build to the stated direction, because that's where the system is moving even if the current behaviour hasn't caught up.
What's the difference between an author bio and an editorial standards page?
The bio answers "who wrote this"; the standards page answers "how we decide what's true". Both are rater-visible trust signals per SQRG §3.3. The bio tells a reader about the author's expertise and experience. The standards page tells them about the process: how content is researched, fact-checked, reviewed, and corrected. You need both.
Is this just for big publishers?
No, and small sites often have an easier time demonstrating first-hand experience than enterprise content farms. A one-person hosting consultancy writing about real client work can ship more credibly non-commodity content than a 50-writer content team paraphrasing each other. The cost of shipping the visible trust stack is the same either way. A solo site can declare "author and editorial reviewer are the same person" openly; enterprise sites have to coordinate sign-off.
Do I need to pass the Rich Results Test to rank?
No. Rankings don't require valid schema. But eligibility for rich results, AI Overview citations, and "Jump to" sitelinks does. A page with broken schema won't rank any worse; it just won't pick up the enhanced SERP presence. Given the Rich Results Test is free and runs in ten seconds, "don't bother" is a bad argument.
Build this on a platform that keeps up
Everything you've seen here ships on 365i hosting: 105 articles with visible reviewer lines, schema that passes Google's Rich Results Test, autoscaling cloud on unlimited LVE resources, and data centres in the UK, US and Asia. Slow hosting won't create E-E-A-T, but it can undo it. Core Web Vitals remain a Page Experience signal and an AI Overview eligibility factor.
See WordPress HostingSources
Google primary sources
- Top ways to ensure your content performs well in Google's AI experiences on Search
- Creating helpful, reliable, people-first content
- Search Quality Rater Guidelines
- What web creators should know about our March 2024 core update and new spam policies
- AI Overviews launch announcement
AI engine sources
Related reading on the 365i property
Published: · Last reviewed: · Written by: Mark McNeece, Founder & Managing Director, 365i
Editorially reviewed by: Mark McNeece on · Our editorial standards