The House of Lords published a 180-page report on 6 March 2026 warning that AI companies are strip-mining copyrighted content from UK websites without permission, payment, or even disclosure. The Communications and Digital Committee's "AI and Copyright" report calls on the government to reject opt-out copyright exceptions and build a licensing-first framework backed by statutory transparency rules.
Most coverage focuses on the music, film, and publishing industries. That makes sense: they're the loudest voices in the room. But the report's implications run far deeper than Spotify royalties and newspaper paywalls. If you run a UK business website with blog posts, service pages, case studies, or product guides, your content is almost certainly being scraped to train AI models too. And right now, you have no legal mechanism to stop it, no way to know it's happening, and no compensation when it does.
What the Report Actually Says

The committee spent months hearing evidence from AI companies, publishers, musicians, artists, and legal experts. Their conclusions are blunt.
UK creative industries contribute £124 billion to the economy and employ 2.4 million people. The AI sector, by comparison, generates £12 billion and employs 86,000. The committee's position: don't sacrifice a proven economic powerhouse for speculative AI gains.
Three specific recommendations stand out for website owners:
No opt-out copyright exceptions. The government had floated a text and data mining (TDM) exception that would let AI companies scrape freely unless creators explicitly opted out. The committee says this puts the burden on the wrong side. Instead, AI developers should need a licence before using copyrighted material for commercial training.
Statutory transparency. AI companies would be legally required to disclose what training data they've used. Right now, nobody outside these companies knows which websites are in the training set. This would change that.
Protection against digital replicas. The report calls for stronger rules against AI-generated content that imitates specific creators' styles or identities. If an AI system can write "in the style of" your brand voice after training on your blog, that's a problem the report wants addressed.
Why This Isn't Just About Musicians and Authors
The media framing of "creative industries vs Big Tech" misses a massive audience: the millions of UK small businesses that publish content online every day.
Think about what's on your website. Service descriptions explaining what you do. Blog posts answering customer questions. Case studies showing your results. Product pages with detailed specifications. FAQ sections, guides, how-to content. All of it written by you or your team, often at considerable cost.
AI crawlers from OpenAI, Google, Anthropic, Meta, and dozens of smaller companies are visiting these pages and ingesting the text. That text then trains models that can answer questions about your industry, sometimes replacing the need for a customer to visit your site at all. Your content helped build a tool that competes with you for attention. The flip side is worth holding onto, though: those same crawlers decide whether AI tools ever mention you, so blanket-blocking them carries its own cost.
Baroness Keeley, the committee chair, put it directly in her statement accompanying the report:
"Watering down the protections in our existing copyright regime to lure the biggest US tech companies is a race to the bottom that does not serve UK interests. We should not sacrifice our creative industries for AI jam tomorrow."
Owen Meredith, chief executive of the News Media Association, was equally direct:
"There is one swift, simple step the Government can take to unlock growth in UK intellectual property: publicly rule out changes to copyright law and allow the market to scale at pace."
The committee found that 95% of industry respondents rejected the government's original opt-out proposals. The government has since abandoned those proposals, but hasn't confirmed what replaces them. An economic impact assessment is due by 18 March 2026.
What UK Website Owners Can Do Right Now

Legislation is coming, but it won't arrive until 2027 at the earliest. In the meantime, you're not powerless. Here's what you can do today.
1. Update your robots.txt to block AI crawlers. Most UK websites still allow every bot through the front door. Our analysis with Cloudflare data found that 72% of UK sites have no AI crawler restrictions in their robots.txt files. Add specific rules for GPTBot, ChatGPT-User, ClaudeBot, Google-Extended, and other AI crawlers. Will they all obey? No. But it establishes your intent, and the Lords' report recommends making that intent legally enforceable.
2. Set up AI discovery files. This is different from blocking. AI discovery files tell AI systems who you are, what you do, and how you want to be represented. They don't prevent scraping on their own, but they create a documented record of your terms. If licensing frameworks arrive, you'll want that record in place. The AI Discovery Files Service can set these up for you, or you can create an llms.txt file yourself.
3. Check what AI already knows about your business. Use the AI Visibility Checker to see what AI systems currently see when they visit your site. You might be surprised. Some businesses find AI models are confidently describing their services using outdated or inaccurate information pulled from old web pages.
4. Document your original content. If licensing becomes law, you'll need to prove what's yours. Keep records of publication dates (your sitemap helps), authorship, and original research. Use our Post Sitemap to CSV tool to export a complete inventory of every page on your site, with titles and URLs, as a baseline record.
5. Host with a UK provider. The committee raised concerns about UK content being processed by AI systems in jurisdictions with weaker copyright protections. Hosting your site on UK-based infrastructure keeps your data governed by UK law. That matters more than it used to.
The Gap Between Now and 2027
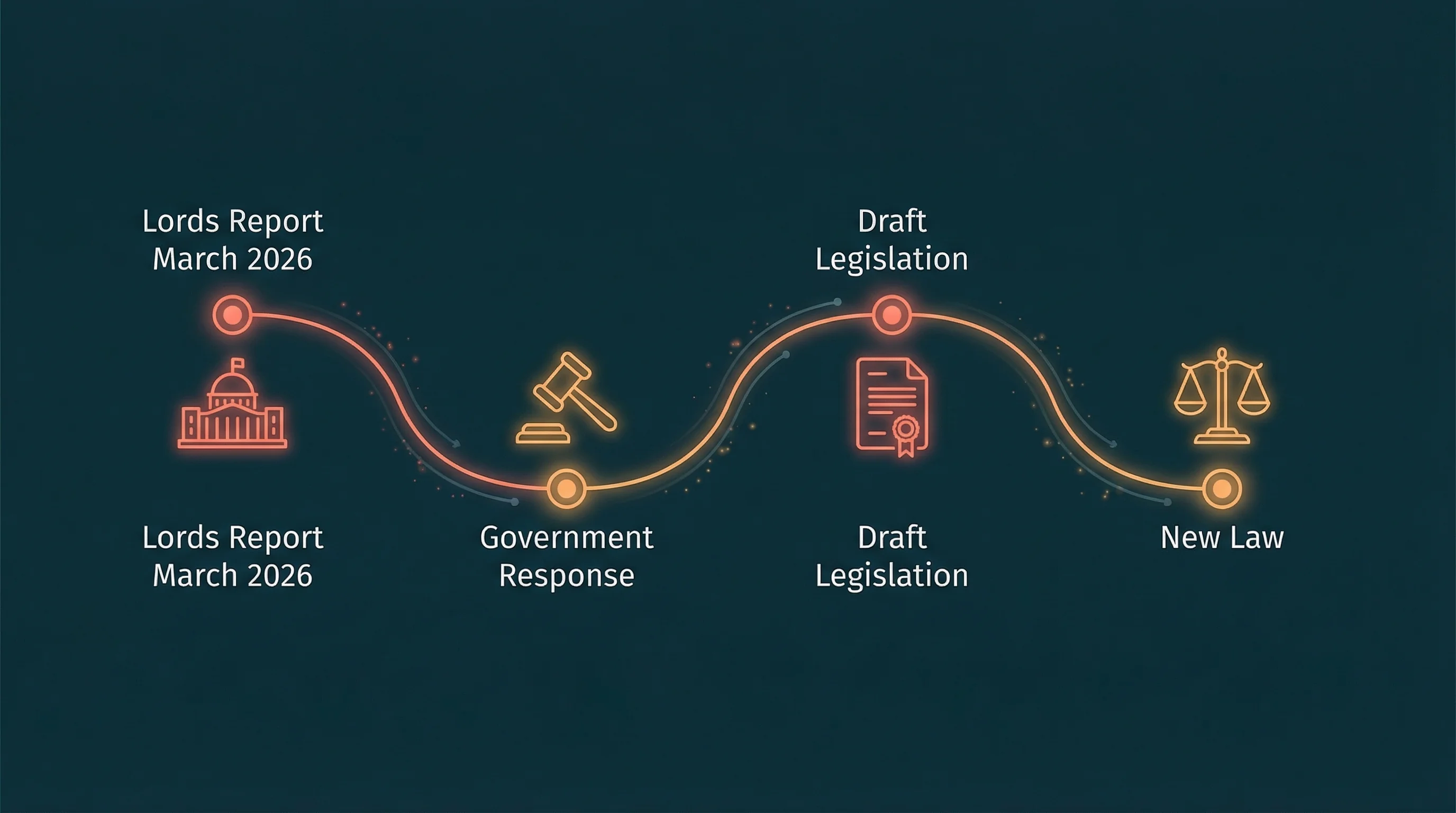
Here's the uncomfortable reality. The committee's recommendations aren't law yet. They're pressure on the government, and significant pressure at that, but the Financial Times reports that ministers have delayed reforms until 2027. In the meantime, AI companies continue scraping.
Tom Kiehl, CEO of UK Music, summed up the stakes at the report's launch:
"The UK is at a crossroads and the Government has a choice to make: either become a global leader in ethical and transparent AI innovation, or sell our incredible cultural and creative sectors down the river to unscrupulous big tech firms."
The UK CMA has already forced Google to let websites opt out of AI Overviews. The Online Safety Act now covers AI chatbots. This Lords report adds a third front to the UK's emerging AI regulatory framework. The direction of travel is clear, even if the timetable isn't.
For UK website owners, the practical question isn't whether to act, but how quickly. Every month you wait is another month of your content being ingested without your knowledge, consent, or compensation. The technical tools to signal your intent exist today. The legal framework to enforce it is on its way.
What to Watch Next
18 March 2026: The government's economic impact assessment on AI and copyright is due. This will indicate whether ministers lean toward the Lords' licensing-first approach or try to find a middle ground that AI companies can live with.
Late 2026: The EU's AI Act enforcement deadline, which will create pressure for UK alignment (or deliberate divergence) on AI transparency and data provenance requirements.
2027: Earliest date for UK legislative action on AI copyright, based on the government's stated timeline.
In the meantime, the practical steps above cost nothing and take less than an hour. Block AI crawlers you don't want. Set up discovery files for the ones you do. Document what's yours. When the law catches up, you'll be ready.
Frequently Asked Questions
Does the Lords report affect my business website, or just creative industries?
It affects any UK website that publishes original content. Blog posts, service pages, product descriptions, case studies, FAQ sections, and guides are all copyrighted works under UK law. AI companies scrape business websites alongside news sites and creative platforms. The report's recommendations would apply to all copyrighted material, not just music, film, or publishing.
How do I know if AI companies are scraping my website?
Check your server logs for user agents like GPTBot, ClaudeBot, ChatGPT-User, Google-Extended, and Bytespider. If you're on managed hosting, your provider may filter these for you. You can also use our free Robots.txt Checker to see which crawlers your current rules allow or block, and the AI Visibility Checker to see what AI systems have already ingested.
Can I block AI crawlers from my website right now?
Yes, using robots.txt directives. Add rules for GPTBot, ChatGPT-User, ClaudeBot, Google-Extended, and other AI-specific user agents. Not all crawlers respect robots.txt, but Cloudflare data shows that sites with explicit AI crawler rules see 43% fewer violations than those without.
What does "licensing-first" mean for website owners?
Under a licensing-first model, AI companies would need permission before using your content for commercial training. The default shifts from "scrape unless told not to" to "ask before you take." This is how stock photography, music licensing, and academic publishing already work. The committee wants the same principle applied to AI training data.
When will new AI copyright laws actually take effect in the UK?
Not before 2027. The government has an economic impact assessment due 18 March 2026, but ministers have delayed legislative action. In the meantime, robots.txt rules and AI discovery files are your best tools for signalling your intent.
What's the difference between robots.txt and AI discovery files?
robots.txt is a blocking mechanism. It tells crawlers "don't access these pages." AI discovery files (llms.txt, ai.json, identity.json) are an identity layer. They tell AI systems "this is who we are, this is what we do, represent us accurately." You need both: robots.txt to control access, and discovery files to control how AI describes your business when it does engage with your content.
Does hosting in the UK help protect my content from AI scraping?
UK hosting means your data is governed by UK copyright law and any future AI licensing requirements. The committee raised concerns about content being processed in jurisdictions with weaker IP protections. Hosting with a UK-based provider keeps your content under the legal framework most likely to enforce AI licensing rules.
Check What AI Crawlers See on Your Website
Your robots.txt rules might be letting every AI crawler through the door. Test them for free and find out which bots you're blocking and which ones you're not.
Check Your Robots.txtSources
Published: · Last reviewed: · Written by: Mark McNeece, Founder & Managing Director, 365i
Editorially reviewed by: Mark McNeece on · Our editorial standards